
A survey on private smart contract construction method (Part2)
Executive Summary
이 문서는 Cyclic Arbitrage in Decentralized Exchanges 논문에서 언급이된 smart contract의 보안성을 높인 private smart contract와 관련된 현재 공개된 기술(기법)에 대해서 조사 및 분석한 결과를 공유하는 글입니다. 지난번 Medium 블로그 글에 이어서 이번에는 Smart Contract의 코드 기밀성을 향상기키기 위한 방법으로 우리에게 익숙한 코드 난독화(Code Obfuscation)을 중심으로 관련 논문 2편을 정리할려고 합니다. 해당 글은 BEARS 팀 세미나에서 발표된 내용이며 BEARS팀 블록체인 스터디에 참여하고 싶으신 분들은 bears.team.kr[AT]gmail.com으로 연락주시면 감사하겠습니다.
Introudction
Private Smart Contract관련 기술조사 1부에서 우리는 여러개의 Private Smart Contract를 지원하는 프레임워크를 아주 간단히 살펴보았다. Private Smart Contract를 지원하기 위한 프레임워크는 기본적인 이더리움과 같은 메인넷 위해서 Private Smart Contract를 지원하기 위한 Layer-2 기능을 수행하는 것으로 파악되었고, 대부분이 이더리움 위에서 동작하는 것으로 판단이 됩니다.
Private Smart Contract를 지원하는 프레임들은 기본적인 큰 틀에서 접근방향이 유사하다고 볼 수 있습니다. 기존의 Solidity 기반 Smart Contract를 두 개로 구분, 사용자 입력, 주요 데이터 코드의 경우 Private한 장소(TEE, VM, 별도의 네트워크)에서 계산하고 이후 암호화된 계산된 결과를 Public 네트워크(예: 이더리움)에 검증을 받는 구조였습니다. 동작, 금액, 사용자에 대한 기밀성을 보장하기위한 서비스입니다. 이러한 동작방식은 Cyclic Arbitrage in DEX 조사시에는 예상하지 못 했던 것입니다. 이 논문을 분석할 때에는 x86/x64에서의 Themida, VMProtect와 같은 코드 난독화 정도의 기술이 적용된 Smart Contract를 Private Smart Contract라 생각했었습니다. 지금와서 생각해보면 난독화(Obfuscation) 기술의 취지 목적(분석자를 지치게 해서 역공학을 포기하게 만들자!)를 생각해보면 Private Smart Contract와는 약간의 거리가 있을 수도 있다라고 생각이 들었어야 했는데 말이죠…
그러나 금액 및 송수신자에 대한 정보는 노출되어도 상관이 없고 보호해야할 대상이 Smart Contract내 존재하는 코드, 핵심 알고리즘으로 제한될 경우 Smart Contract 코드 난독화 또한 충분한 가치가 있다고 생각이 듭니다. 예를 들어, 여러분들이 윈도우에서 어떤 프로그램의 기능을 역공학을 통해 알아내야한다고 생각해봅다면, 비슷한 기능을 하는 윈도우 기반 프로그램이 다수 존재할 때 지금 현재 분석을 할려고 하는 프로그램이 Themida로 팩킹이 되어있다면, 팩된 프로그램을 분석하기 보다, 비슷한 기능을 하는 다른 프로그램을 살펴볼 것이며 가능한 팩킹되지 않는 대상을 리버싱을 통해 기능을 분석할 것입니다. 비슷한 예를 블록체인에 찾아보면 다음과 같습니다. 이더리움, 솔라나와 같은 핫한 메인넷에는 시세차익 거래를 하는 다양한 봇들이 있습니다. 이 봇들을 개발하는 회사들은 자기를 봇의 시세차익 거래 알고리즘을 지키고 싶을 것입니다. 만약 x86/x64에서의 UPX 정도로 팩킹된 봇이 있다면 해당 봇은 알고리즘을 다른 경쟁회사에서 헌납하는 경우와 동일한 것입니다. 만약에 Themida나 VMProtect 수준으로 난독화 되어 있다면, 역공학 분석자는 그 시간에 다른 회사 봇을 분석할 것입니다. 상대적인 난이도 차이로 봇의 핵심 기술을 지킨 것입니다.
저는 기본적으로 1부에서 목록화한 Private Smart Contract 서비스대비 코드 난독화 기술이 실제 메인넷에서 스마트컨트렉트가 배포되기까지 과정이 간단하기 때문에 Private Smart Contract 서비스 사용하는 경우대비 속도적 측면에서 이점이 있을 것으로 판단됩니다. 다만 앞에서도 언급하였지만 코드 난독화가 가지고 있는 태생적인 한계점이 존재하기 때문에 이 점은 Solidity 난독화에서도 동일하게 적용됩니다.
본 블로그에서는 두 편의 Solidity기반 Smart Contract 코드 난독화 논문을 살펴볼 것이고, 한 논문의 경우는 github에 소스코드 또한 공개한 상태입니다. 두 편의 논문을 먼저 읽어본 저 개인적인 느낌은 두 편 모두 뭔가 좀 부족한데?라는 것이며, 그 부족한 부분을 우리 스터디 그룹에서 채워서 괜찮은 난독화 도구를 만들면 되지 않을까?라는 생각을 해봤습니다.
Source Code Obfuscation for Smart Contracts
Motivation
이 논문의 경우 Solidity 코드 난독화 연구를 착수한 동기가 기존의 보안연구의 목적과 사뭇 다릅니다. 저자들이 Solidity 코드 난독화 연구를 착수한 동기는 기존의 EVM 바이트코드를 Solidity 코드로 변환해주는 도구를이 있는데 이들의 성능을 공정하게 평가할 적절한 테스트을 만드는 것이 어려워서 다양한 테스트 세트를 만들기한 도구를 만드는 것입니다. 그래서 난독화된 코드에 대한 가독화를 기준으로 여러 디스어셈 도구들 간에 깊이있는 평가에 기여한다는 것입니다. 이러만 목적으로 개발한 Solidity 도구 난독화 도구로 BiAn을 제안하며, BiAn이 Solidity 난독화를 위해 지원하는 기법으로 아래의 것들을 나열하고 있습니다.
- obfuscating a contract’s control flow
- obfuscating a contract’s data flow
- obfuscating a contract’s layout
논문에서 BiAn 도구의 활용법으로 3가지를 제안하고 있습니다.
- Generate obfuscated test cases to evaluate static analysis tool(직접적인 연구동기)
- Obfuscate contracts to protect the contracts from reversing
- Generate the obfuscated versions of public datasets to expand the size of public datasets
Proposed Model(Approach)
이 논문에서는 Solidity 코드에 대한 난독화(Obfuscation)과정을 3단계로 구성하고 있습니다.
STEP1: Control flow obfuscation
첫번째 단계에서는 Control flow obfuscation입니다. Control flow obfuscation의 과정은 다음과 같습니다.
- Parsing the source code based on control flow graph(CFG)
- inserting opaque predicates : 어떤 더미코드를 삽입하는지 소스코드 분석을 통해서 확인이 필요할 것 같습니다. 개인적으로 IDA Pro를 예로하면 한 바이트 삽을 통해 디스어셈블리가 어렵게 만드는 것과 동일하다고 생각했었는데, 논문에서는 더미 분기문을 많이 만들어내는 코드 조작을 삽입하는 것으로 판단되며, 아마도 분석자가 보기에 지나치게 함수를 복잡하게 만들어 심리적으로 분석에 대한 부담을 주면서, 쓸데없는 코드 해석에 시간을 많이 소모하게 만드는 접근을 논문의 저자들은 생각한 것 같습니다.
- flattening the control flow : 일반적인 x86/x64에서는 반복문과 같은 코드를 쭉 풀어서 길게 늘려놔서, IDA Pro내 그래프뷰(Graph View)에서 함수를 구조적으로 분석하기 힘들게 하는 것을 의미합니다. 논문에서는 이부분에 Basic Block Logic(BBL)을 마구 흐트려서(scramble) 코드 블록간의 관계를 약하게 한다라고 기술하고 있는데, 이 것이 정확하게 어떻게 하겠다는 건지는 추후에 BiAn 코드 분석을 통해 확인이 필요할 것 같습니다.
STEP2: Data flow obfuscation
두 번째 단계는 데이터 흐름(Data flow)에 대한 난독화입니다. 호출 흠름에서 CFG기반으로 분석했던 것 처럼 데이터 흐름 분석을 위해 abstract syntax tree(AST)기반으로 스마트컨트렉트를 분석하게 됩니다. CFG분석 AST분석의 경우 solidity 퍼징에서 기본적으로 스마트 컨트렉트를 분석할 때 기본적으로 사용하는 기법으로 구글 검색을 하면 다양한 오픈소스 프로젝트를 확인할 수 있습니다. 현재 BEARS팀에서 개발한 Solidity 퍼저의 경우에도 퍼징을 위해 CFG, AST 분석을 기본적으로 하고 있습니다. 따라서 이 글을 읽으시는 여러분들도 CFG, AST 분석의 경우는 쉽게 구현할 수 있습니다.
데이터 흐름 난독화는 크게 3가지 부분으로 구성되어 있습니다.
- Changing coding style
- Replacing constants
- Modifying storage types
Change coding style 단계에는 저자달은 변수의 의미를 제거하였다라고 설명하고 있는데 예로 b라는 boolean 변수가 존재할 때, 이 변수를 다른 두개의 boolean 변수 p, q로 쪼개어 b를 p&q로 변경하는 것을 들고 있습니다. 기존식에서 양쪽에 동일한 의미의 다항식을 다양하게 추가함으로써 분석자의 혼란을 가중할 수 있을 것 같습니다. Replacing constants에 대해서는 적분상수(integral constant)를 산술식(arithmetic) 형식으로 변경 시켰다라고 설명하고 있습니다. 아지막 Modifying storage types에서는 Solidity에 존재하는 상태변수에 대해서 구조체 형태로 변경하여 구조체의 멤버로 접근하는 구조로 변경하고, 또한 로컬 변수로 재선언하여 사용하는 등 역공학 도구로 분석시 최대한 혼란을 가중시키는 방법을 제안하고 있습니다.
STEP3: Layout obfuscation
Layout obfuscation의 의미는 역공하는 분석자가 디스어셈을 기반으로 코드를 분석할 때의 부담을 증가시키는 것을 의미한다고 논문에 기술하고 있습니다. 이 것을 위해서 저자들은 코드에서 추가적인 정보가 될 수 있는 모든 것을 제거했다라고 하고 예로 소스코드 주석을 제거했다하고 언급하고 있으며, Solidity의 주소조합 공식에 따르면 40bit의 해쉬를 사용하고 있는데, 임의의 40비트 해쉬값으로 모든 식별자를 변경하는 기능이 있다라고 기술하고 있습니다. 이렇게 함으로서 얻을 수 있는 이득은 역공학 분석자에게 40비트 해쉬값중 주소를 식별하는 부담을 가중시키는 효과가 있을 것 같습니다.
Evaluation
Experimental Dataset의 구성 및 실험과정
논문의 실험 데이터는 10가지의 오랜된 유형의 취약점을 가지고 있는 44개의 스마트컨트렉트를 입수하여 각 스마트 컨트렉트별 취약점 유형을 태깅(Tagging)후, 모든 실험 대상 스마트컨트렉트를 난독화 합니다. 난독화 스마트 컨트렉트와 난독화 하지 않은 스마트컨트렉트를 대상으로 정적분석도구를 돌려서 취약점을 잘 탐지하는지 여부를 확인하는 방식으로 난독화 성능을 평가하였습니다. 이렇게 실험을 구성하는게 과연 난독화 성능을 잘 평가하는 방법인지는 약간의 토의를 해봐야 할 것 같지만, 스마트컨트렉트의 고전 취약점을 정적분석 도구를 활용해 빠르게 탐지하여 토큰을 훔칠려는 공격자를 대상으로 한다면 의미가 있는 실험으로 볼 수 있으나, 대부분 공격자들은 직접 리버싱을 할 가능성이 높기 때문에, 난독화된 코드를 실제로 살펴봄으로서 평가를 해야할 것으로 판단됩니다. 마지막으로 스마트컨트렉트는 solc로 컴파일하여 바이트코드를 생성하였습니다.
Evaluate the effeciency of BiAn with respect to complexity
메인 실험이전에 논문에서는 본인들이 개발한 BiAn도구가 얼마나 많이 스마트컨트렉트를 복잡하게 만드는지 확인하는 실험을 실시하였습니다. 얼마나 복잡하냐?라는 질문에 대한 판단기준으로 컨트렉트내 패스의 개수를 계산하였고, 이 계산을 하는 도구로 Vandal이라는 스마트컨트렉트 디컴파일러를 활용하였습니다. 실험 결과를 보면 BiAn 결과물들이 원 스마트컨트렉트 대비 복잡도(Path의 개수)가 많이 높아진 것을 확인 할 수 있고, 패스의 복잡도 향상대비 가스비의 증가는 상대적으로 낮아, 비용대비 복잡도 증가는 효율적이다라고 평가할 수 있습니다. 복잡도(complexity)에 대한 평가를 경로 개수의 증가만으로 평가하는 것이 올바른지는 논란이 있을 수 있지만,
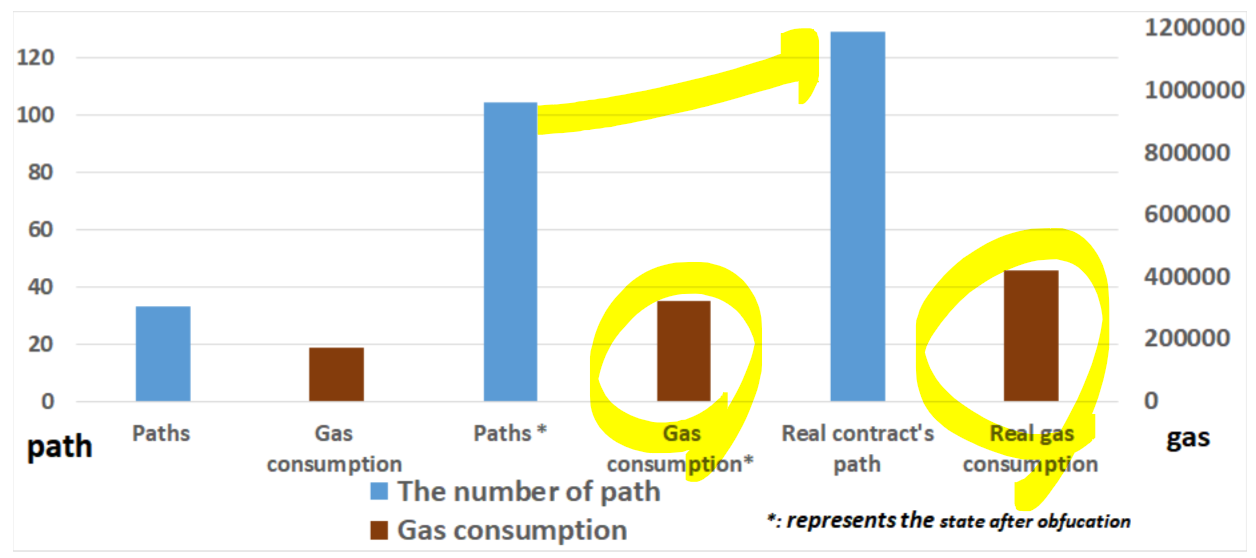 |
|---|
| 그림.1 Change in complexity and gas consumption |
Evaluate the effectiveness of BiAn against 9 solidity static analysis tools
논문의 그림2는 논문의 그림을 두개로 나누어서 재구성했습니다. 실제 논문의 그림은 너무 작아서 컬러 출력해서 종이로 논문을 보면 글자가 확인이 안 될 정도입니다. 그래서 글자를 확인할 수 있는 수준으로 그림을 확대한 후, 그림을 재구성하였습니다. 그림 2-1과 2-2를 살펴보면 바로 결과를 알 수 있는데, 난독화한 코드의 경우 정적분석 도구들이 취약점 탐지에 상당히 실패하는 것을 확인할 수 있습니다.
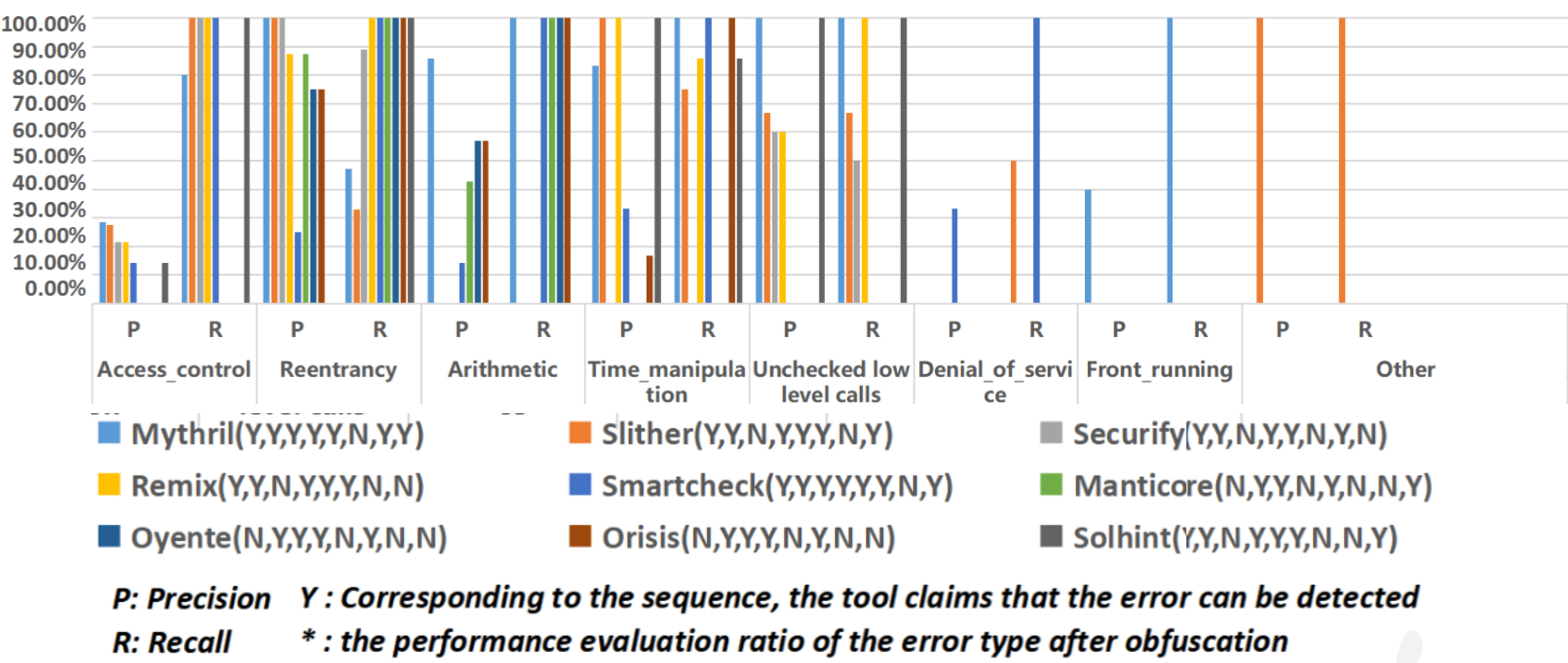 |
|---|
| 그림.2-1 The experimental results of smart contract detection using statis analysis tools |
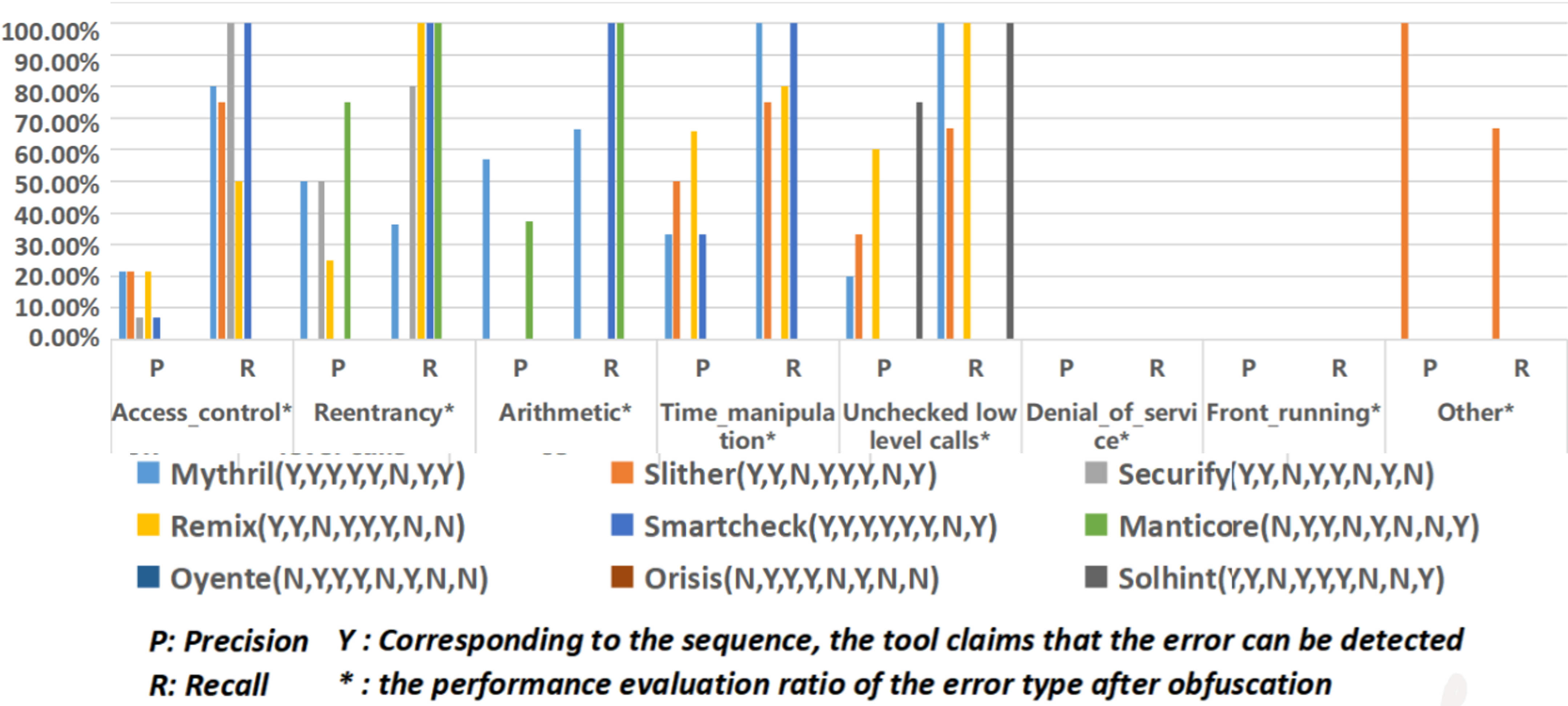 |
|---|
| 그림.2-2 The experimental results of smart contract detection using statis analysis tools |
일차적으로 BiAn 논문에 대한 정리는 이정도로 실시하고, 이후에 BiAn을 사용하면서 실제 EVM 바이트 코드가 얼마나 복잡해지는지는 추가적으로 다뤄볼 계획입니다.(BiAn과 EShield에 대한 내용은 이 포스트에 점진적으로 계속 추가하겠습니다.) 아래 그림은 BiAn 사용 전/후의 스마트컨트렉트 변화이며, Layout obfuscation에서 말한 40bit 해쉬로 변수 이름을 대체한다는 것에 대한 명확한 뜻을 이해하는데 도움이 될 것입니다.
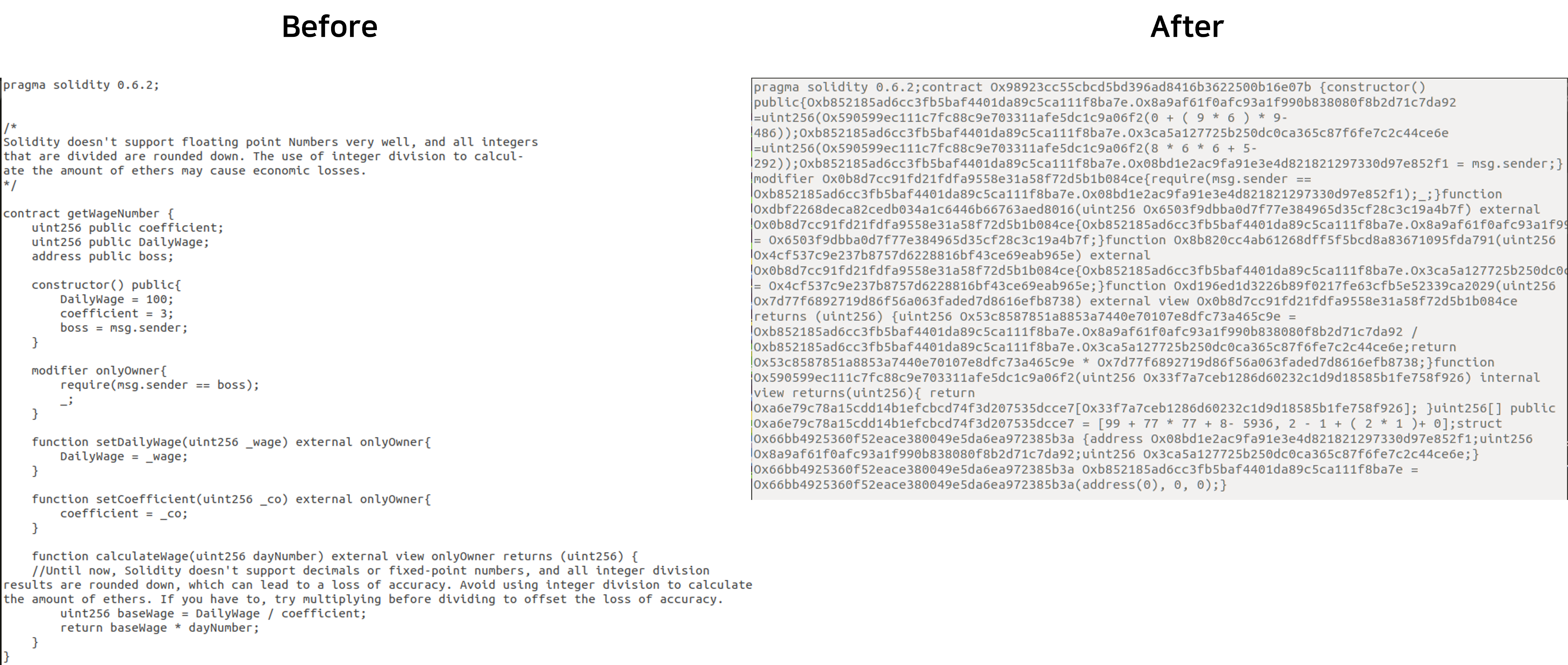 |
|---|
| 그림.3 The comparison between before and after using BiAn |
EShield
두 번째로 살펴볼 논문은 “EShield: Protect Smart Contracts against Reverse Engineering” 입니다. 첫번째 논문과 같이 중국 대학에서 연구한 논문입니다. EShield의 목표는 스마트 컨트렉트 난독화를 통해 리버싱 공격에 대비하여 스마트컨트렉트의 본안성을 높이는 것입니다. 실험도 첫번째 논문대비 약 2만개의 스마트 컨트렉트를 대상으로 3가지 종류의 역공학 도구(reverse engineering)에 대해서 얼마나 스마트컨트렉트를 보호할 수 있는지를 실험하였습니다. 상대적으로 첫 번째 논문대비 실험에 대한 신뢰가 높다고 할 수 있습니다. 다만 EShield의 경우 BiAn과 달리 소스코드를 공개하고 있지 않기 때문에, 실제적인 구조 및 실험결과에 대한 재검증이 어려울 것으로 판단됩니다.
Motivation & Contribution
논문에서 얘기하고 있는 Solidity 보안관련 상황을 다음과 같이 설명하고 있습니다.
- Erays와 같은 EVM 바이트코드를 리버싱할 수 있는 역공학 도구가 발전하고 있으며, 이러한 도구를 활용하여 정당하지 않은 이익을 얻기위한 시도가 많이 발생하고 있다.
- 그러나 이와 관련해서 기존에공개된 Anti-reversing 기술들은 비효과적이고 또한 가스비적 측면에서 비효율적이다.
이러한 환경에서 역공학(reverse engineering)기술로 부터 스마트컨트렉트를 보호하기 위한 기술개발에서 사전에 풀어야할 문제를 2가지로 요약하고 있습니다.
- Challenge 1(Non Von Neumann Virtual Machine) : EVM은 표준 폰 노이만 구조를 따르지 않기 때문에 실행중에 코드 수정이 불가능하기 때문에, 암호화된 코드를 동적으로 복호화 하면서 실행할 수 가 없다.
- Challenge 2(Gas Cost) : 일반적으로 난독화(Obfuscation)은 실행 코드양을 증가시킴으로 자연스럽게 이더리움 가스비의 증가로 이러진다. 지금 현재는 문제인 것은 맞는데, 만약 이더리움이 PoS체계로 전환이되면, 가스비문제는 자연스럽게 해결될 가능성도 있습니다. 하지만 지금의 이더리움에서는 높은 가스비는 난독화 기술을 적용하는데 장애물인 것은 틀림없습니다.
그래서 이러난 어려움을 다 해결하고, 스마트컨트렉트의 코드 보안을 향상사킬 수 있는 기술로 이 논문에서 EShield를 제안하고 있습니다.
Proposed Model
Solidity 소스코드를 입력으로 받아서 난독화하여 코드 복잡도를 증가시키는 접근을 사용하는 것에 반하여, EShield의 경우에는 컴파일된 바아티코드를 입력 데이터로 사용, 이를 기반으로 난독화를 하게 됩니다.
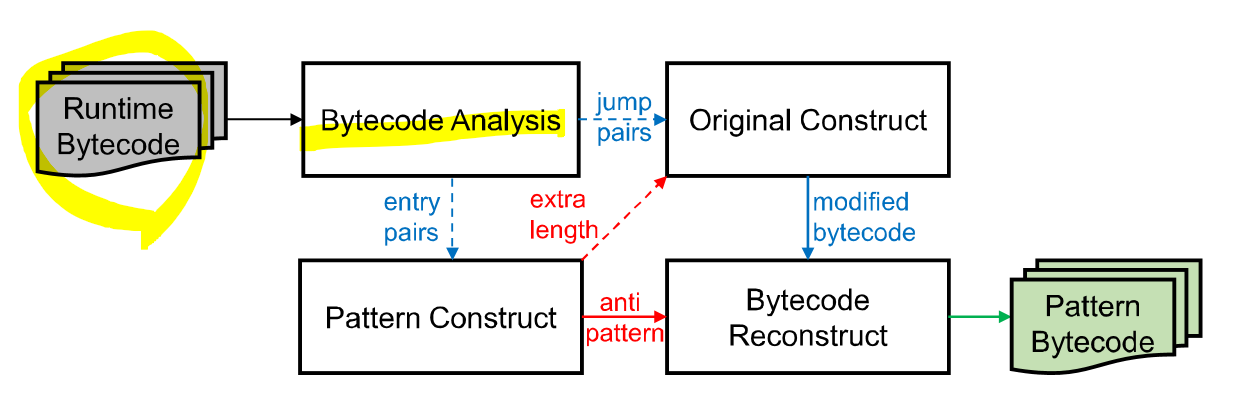 |
|---|
| 그림.1 The framework of EShield |
그림 1.을 살펴보면 가장 중요한 역활을 담당하는 것은 Bytecode Analysis과 Pattern Contruct라고 할 수 있습니다. Bytescode Analysis는 입력된 바이트코드로 부터 CFG 정보를 생성해서, 이를 기반으로 anti-pattern을 삽입할 적절한 포지션을 찾아내고, Pattern Construct는 해당 위치에 삽입할 적절한 anti-pattern를 생성합니다. 이를 기반으로 Orignal Construct는 anti-pattern을 삽입할 적절한 공간을 만들고 Bytescode Reconstruct에서 제공받은 anti-pattern를 삽입하여 난독화된 컨트렉트를 만들게 됩니다.
여기서 우리가 가장 중요하게 봐야할 것은 Bytescode Analysis가 어떻게 적절한 anti-pattern 지점을 선정하는지, 그리고 Pattern Construct가 Byteacode Analysis가 선정한 위치에 들어갈 적절한 anti-pattern을 어떻게 생성하는지 이 두가지 포인트입니다.
Bytecode Analysis
EShield에서 CFG를 생성하기 위해 기존에 오픈소스 evm cfg-builder를 사용합니다. CFG를 만들면서 jump-pairs를 만들게 되는데, jump-pairs는 단순하게 JUMP, JUMPI 명령어와 점프 명령과 주소의 쌍을 key-value(예, 파이썬 사전형 자료구조) 형태로 저장한 것입니다. 추가적으로 3가지의 데이터를 더 추가되는데, 세가지 데이터는 다음과 같습니다.
- the function address of JUMP(I)
- the position between JUMP(I) and its jump address
- the length of jump address
그리고 entry-pair라는 것도 생성하는 하는데, entry는 x86/x86에서 함수의 prologue라고 생각하면 되고 EVM에서는 EQ-PUSH-JUMPI의 패턴을 가집니다. 모든 entry 인스트럭션을 분석해서 JUMPI에 함수 주소와 함께 마킹을 한 것이 entry-pair입니다. 모든 entry-pair는 anti-pattern이 삽입되는 위치로 사용된다고 논문은 기술하고 있습니다.
Anti-pattern Construct
EShield에서 지원하는 anti-pattern의 종류는 4가지입니다. 각 anti-pattern을 간단하게 요약정리하면 다음과 같습니다.
- Pattern1: jump 주소에 대한 난독화(MSTORE/MLOAD 명령과 스택 사용)
- Pattern2: jump 주소에 대한 난독화(SSTORE/SLOAD 명령과 스토리지 사용)
- Pattern3: SHA3와 EShield 특수 명령조합을 통한 함수주소 난독화
- Pattern4: 외부 스마트 컨트렉트의 함수 호출을 활용한 JUMP 주소 생성
EShield의 모든 난독화 기술이 호출 흐름을 난독화하기 위한 JUMP 주소 난독만 패턴만 지원하는 것을 확인할 수 있습니다. 일단 단순한 접근으로 호출 주소 난독화 + BiAn의 몇가지 난독화를 합쳐도 괜찮은 난독화 도구가 될 수 있을 것 같습니다. 두개의 난독화 입력이 다른데, BiAn으로 소스코드 수준에서 난독화 후 solc로 EVM 바이트 코드로 컴파일하고 이 바이트코드를 입력으로 EShield의 JUMP 주소 난독화를 한다면 괜찮은 결과를 얻을 수 있을 것 같습니다.
Original Construct
Original constructor의 역활은 원본 바이트코드를 anti-pattern 삽입이 가능한 형태로 변경하는 역활을 담당합니다. 바이트코드 재구축은 3단계로 구성되어 있으며, 각 단계별 내용은 다음과 같습니다.
- If the jump address is behind the position of entry, the constructor will add extra length and the address value
- calculate all the extra length produced by increasing length of jump address
- calculate the change of length in other addressses : x86/x64에 대입해보면 코드 패치를 하는 중에 추가적으로 바이트가 더해졌기 때문에, 전체적으로 JUMP 오프셋이 변경됨으로 오프셋 값을 수정해주는 것과 동일한 과정입니다.
Implementation
EShield의 구현부분은 크게 4가지로 구분되어 있으며, 그 구조는 그림 2.에 표현되어 있습니다. 개인적으로 그림 1.과 크게 다른 점은 없다고 판단되며, 그림 1. 설명에서 언급이 되었던 evm cfg-builder같은 것들이 그림으로 표현되어 있다.정도 말고는 차이점이 없다고 생각됩니다.
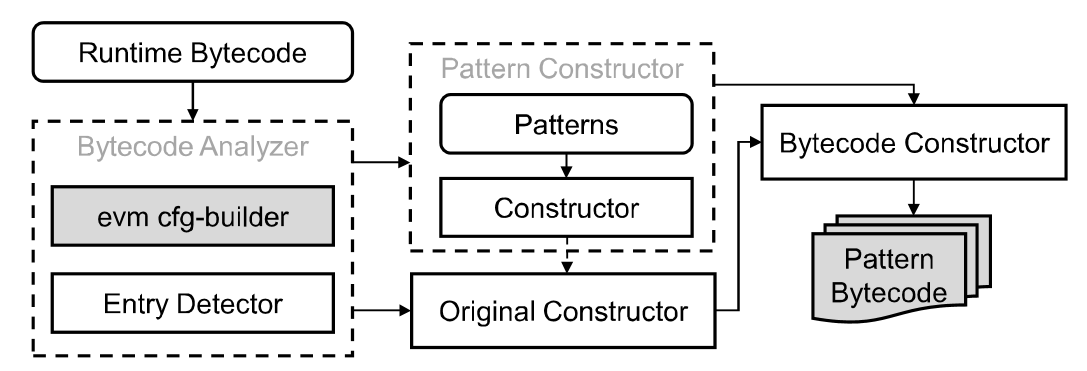 |
|---|
| 그림.2 The architecture of EShield in implementation |
- Bytecode Analyzer : evm-cfg-builder + entry detector
- Pattern Constructor : Bytecode Analyzer로 부터 entry pairs정보를 받아 적절한 anti-pattern을 생성함
- Original constructor : anti-pattern 삽입이 용이하게, 입력 바이트코드를 수정하는 역활을 담당
- Bytecode Constructor : Insert the anti-patterns into the modified bytecode to replace the old entry bytecode.
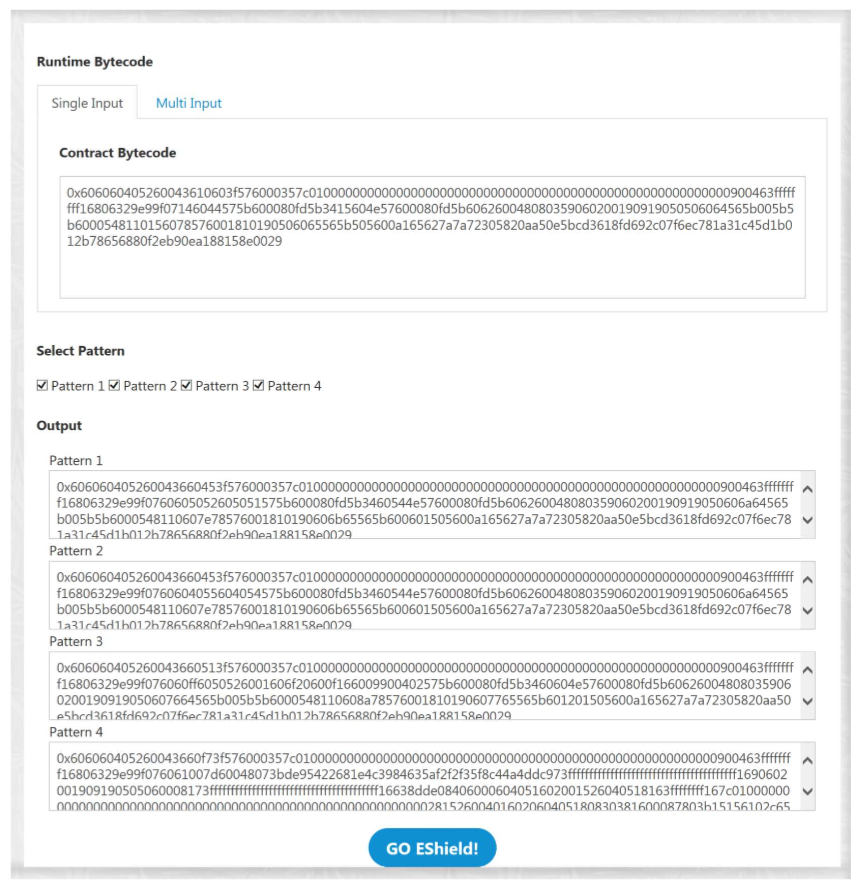 |
|---|
| 그림.3 EShield Screenshot |
Experiments
- Download 20,266 smart contracts
- EShield generates 4 different patterns of protected bytescodes for each smart contract
- User VM(1 vCPU, 6G RAM, Ubuntu 18.04)
- Reverse Engineering Tools : Erays, Vandal, Gigahorse 위 도구들중 IDA Pro와 같은 상용화 도구는 없으며, 다 오픈소스이며, 학계에서 제안된 도구들입니다.
- Matrix : Partially Failed(PF), Entirely Failed(EF)
- PF : 역공학 도구들이 잘못된 결과를 출력하는 경우
- EF : 역공학 도구들이 어떤한 결과도 출력하지 못 하는 경우(역공학 자체가 실패)
Evaluation
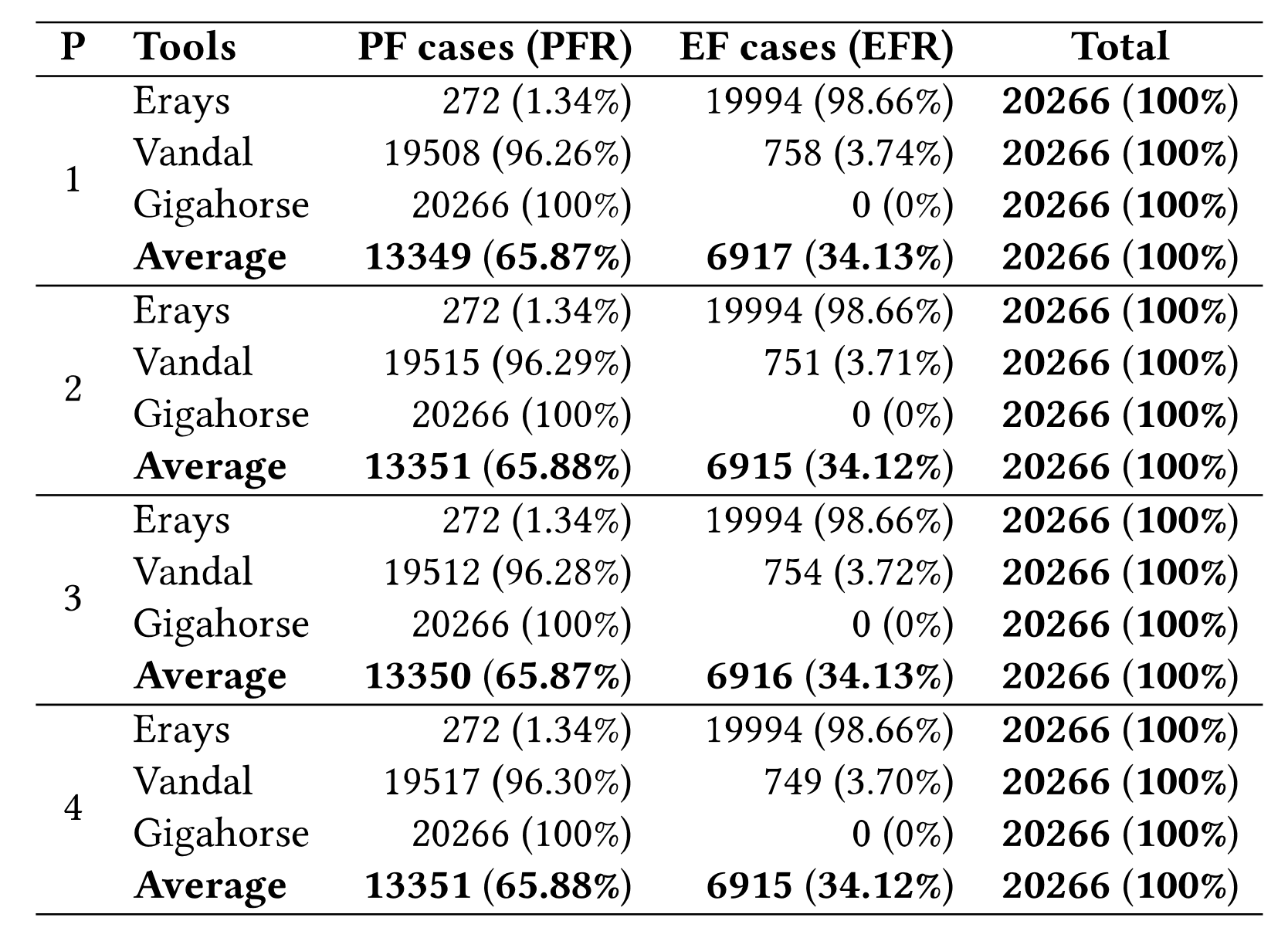 |
|---|
| 표.1 Evaluation Results, P:Patterns |
표.1을 보면, Vandal, Gigahosrse를 보면 EF가 낮고, PF가 높은 것을 확인할 수 있다. 즉 부분적으로 실패했다는 것인데, 부분적으로 실패했다는 것이 정적분석기가 정상적으로 동작하지 않았다는 것을 의미함으로, 도구를 활용한 정적분석을 실패했다라고 볼 수 있다. 부분적으로 분석이 성공한 부분의 수준이 어느정도의 수준인지 분석하는 부분도 있으면 더욱 가치가 있었을 것 같은데, 그 부분에 대한 분석은 이 논문에 없었습니다. PF, EF 두 개를 더하면 100%로 임으로 그 어떤 정적분석기도 정적분석에 성공한 케이스가 없었다는 것도 의미있는 결론이라고 판단됩니다. 마지막으로 etherscan과 같은 사이트에서 제공하는 EVM 바이트 디스어셈블리 수준에서 해당 컨트렉트를 사람이 분석 가능한지에 대한 여부를 개인적으로 확인해 보고 싶은데, EShield의 경우 소스가 공개되지 않아 확인할 수 없는게 조금 아쉽습니다.
|
|---|
| 표.2 Cost of Using EShield. P:Patterns \({Extra}_{Create}\): Extra gas cost of Creating protected contract, \({Extra}_{Dollars}\): Extra cost in dollars, \({Extra}_{call}\): Extra gas cost of Calling protected contracts, \({Extra}_{Dollar}\): Extra cost in dollars, Time: average Time cost of running EShield. |
표.2에서 확인할 수 있는 사실은 일단 난독화(Obfuscation)하면 무조건 가스비가 증가한다. Pattern4 외부 컨트텍트를 활용해서 난독화하는 패턴이 가장 가스비 증가가 높다고 볼수 있지만 하지만 4가지 패턴의 수행시간 측면에서는 별 차이가 없다라고 볼 수 있습니다. 4가지 패턴중에 어는 패턴이 보안적으로 더욱 안전한가? 이 것에 대한 실험이 없는게 개인적으로 아쉬웠습니다. 보안성 대비, 가스비의 비율값을 도출할 수 있다면, 앞으로 난독화를 할 때 Complexity우선 난독화 가스비우선 난독화와 같은 다양한 모드 개발도 가능하고, 기능적 측면에서 보다 완성도 있는 도구 개발이 가능하지 않을까? 생각해봤습니다.
Conclusions
우리는 이번 포스트에서 Solidity기반 스마트컨트렉트의 난독화관련 논문 2개를 살펴보았습니다. 첫번째 살펴본 BiAn의 경우는 소스코드 기반이였으며, 주소 난독화를 포함하여 소스코드 수준에서 난독화할 수 있는 4가지 패턴의 난독화를 사용하였습니다. 비록 논문의 목적이 난독화 자체 기술 개발이 아니라 정적분석기를 올바르게 성능평가할 수 있는 테스트 세트를 생성할 수 있는 도구개발이였지만, 소스코드 수준에서의 난독화 최초의 연구라는 점에서 의의가 있다라고 생가됩니다. 두 번째 난독화 연구는 EShield는 BiAn과 달리 EVM 바이트코드를 입력으로받아 JUMP 명령어와 관련된 주소를 난독화하는데 초점을 두고, 주소 난독화만 서로다른 4가지 패턴으로 수행하였습니다. 실험 깊이면에서는 EShield가 좀 더 많은 대상으로 실시하여, 신뢰도는 상대적으로 높아보이지만, 두 도구다 난독화 측면에서는 공개된 정적분석기를 대상으로 의미있는 결과를 도출했다고 보입니다. 앞에서도 이미 말했지만, 소스코드 난독화 BiAn와 EShield를 연결하여, 소스코드 수준에서 한 번 난독화하고, 이를 컴파일하여 바이트코드 수준에서 주소 난독화까지 한다면 강력한 난독화 도구 개발이 가능할 것으로 판단됩니다. 실제로 난독화 도구에 대한 소스분석을 통하여 아이디어 도출을 하고, 이를 바탕으로 접근하면 디스어셈블리 기반의 수동 분석에도 대응할 수 있을 것으로 판단됩니다.
References
- Source Code Obfuscation for Smart Contracts
- EShield: Protect Smart Contracts against Reverse Engineering
- https://github.com/crytic/evm_cfg_builder